Leetcode 2583 二叉树中的第 K 大层和
2583.二叉树中的第 K 大层和
给你一棵二叉树的根节点 root 和一个正整数 k 。
树中的 层和 是指 同一层 上节点值的总和。
返回树中第 k 大的层和(不一定不同)。如果树少于 k 层,则返回 -1 。
注意,如果两个节点与根节点的距离相同,则认为它们在同一层。
示例 1:
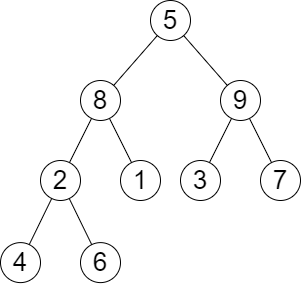
输入: root = [5,8,9,2,1,3,7,4,6], k = 2
输出: 13
解释: 树中每一层的层和分别是:
- Level 1: 5
- Level 2: 8 + 9 = 17
- Level 3: 2 + 1 + 3 + 7 = 13
- Level 4: 4 + 6 = 10 第 2 大的层和等于 13 。
示例 2:
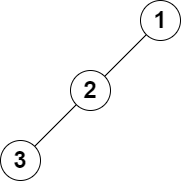
输入: root = [1,2,null,3], k = 1
输出: 3
解释: 最大的层和是 3 。
提示:
- 树中的节点数为
n 2 <= n <= 10^51 <= Node.val <= 10^61 <= k <= n
Related Topics
- 树
- 广度优先搜索
- 二叉树
- 排序
题目链接: link
解答
本题的难度是 Medium.
我们要知道第K大的层的和, 首先那我们就需要知道每一层的和, 然后再排序, 最后取第K大的和. 这是很直接的想法, 知道每一层的和用层序遍历, 前序遍历都行.
代码如下:
class Solution {
private List<Long> list = new ArrayList<>();
public long kthLargestLevelSum(TreeNode root, int k) {
preorder(root, 0);
if (k > list.size()){
return -1;
} else {
list.sort(Comparator.reverseOrder());
return list.get(k-1);
}
}
private void preorder(TreeNode node, int depth) {
if (node == null) {return ;}
if (list.size() == depth){
list.add((long) node.val);
} else {
list.set(depth, list.get(depth)+node.val);
}
preorder(node.left, depth+1);
preorder(node.right, depth+1);
}
}
耗时 41ms, 击败了 29.19% 的提交. 这击败的好少, 于是我改了改, 因为这里耗时很大的原因可能是因为用List, 并且用了官方的排序, 因此试图改这里. 最多 100_000 个元素, 因此最多 100_000 层, 所以用一个数组存每一层的和, 至于第 K 大, 又不用排序, 我们很自然地会想到用堆.
代码如下:
class Solution {
private long[] bucket = new long[100_000];
private int maxDepth = -1;
public long kthLargestLevelSum(TreeNode root, int k) {
preorder(root, 0);
if (k > maxDepth+1){
return -1;
} else {
PriorityQueue<Long> minHeap = new PriorityQueue<>();
for (int i = 0; i<= maxDepth; i++) {
minHeap.add(bucket[i]);
if (minHeap.size() > k) {
minHeap.poll();
}
}
return minHeap.peek();
}
}
private void preorder(TreeNode node, int depth) {
if (node == null) {return ;}
if(depth > maxDepth) { maxDepth = depth;}
bucket[depth] += node.val;
preorder(node.left, depth+1);
preorder(node.right, depth+1);
}
}
此时耗时 36ms, 击败了 46.95% 的提交, 那么我们要怎么再提升呢? 虽然我们去掉了 List, 但是又引入了 PriorityQueue, 这个是不是也是耗时的原因呢? 我们可以试试看, 把 PriorityQueue 换成 Arrays.sort.
class Solution {
private long[] bucket = new long[100_000];
private int maxDepth = -1;
public long kthLargestLevelSum(TreeNode root, int k) {
preorder(root, 0);
if (k > maxDepth+1){
return -1;
} else {
long[] result = Arrays.copyOfRange(bucket, 0, maxDepth+1);
Arrays.sort(result);
return result[maxDepth+1-k];
}
}
private void preorder(TreeNode node, int depth) {
if (node == null) {return ;}
if(depth > maxDepth) { maxDepth = depth;}
bucket[depth] += node.val;
preorder(node.left, depth+1);
preorder(node.right, depth+1);
}
}
果然提升明显, 一下就提升到了 19ms, 击败了 72.34% 的提交, 我在想会不会因为用了 Array.copyOfRange, 导致的耗时, 结果发现居然还有这个函数 Arrays.sort(long[], int fromIndex, int toIndex), 于是我试试看, 发现时间开销并没有更好, 可能要自己手写快排才会更快了, 但是懒得写捏.