Leetcode 2641 二叉树的堂兄弟节点 II
2641.二叉树的堂兄弟节点 II
给你一棵二叉树的根 root ,请你将每个节点的值替换成该节点的所有 堂兄弟节点值的和 。
如果两个节点在树中有相同的深度且它们的父节点不同,那么它们互为 堂兄弟 。
请你返回修改值之后,树的根 root 。
注意,一个节点的深度指的是从树根节点到这个节点经过的边数。
示例 1:
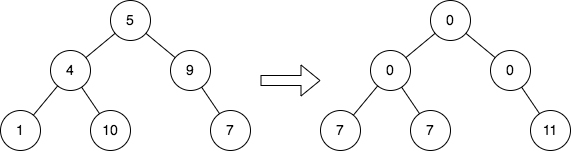
输入: root = [5,4,9,1,10,null,7]
输出: [0,0,0,7,7,null,11]
解释: 上图展示了初始的二叉树和修改每个节点的值之后的二叉树。
- 值为 5 的节点没有堂兄弟,所以值修改为 0 。
- 值为 4 的节点没有堂兄弟,所以值修改为 0 。
- 值为 9 的节点没有堂兄弟,所以值修改为 0 。
- 值为 1 的节点有一个堂兄弟,值为 7 ,所以值修改为 7 。
- 值为 10 的节点有一个堂兄弟,值为 7 ,所以值修改为 7 。
- 值为 7 的节点有两个堂兄弟,值分别为 1 和 10 ,所以值修改为 11 。
示例 2:

输入: root = [3,1,2]
输出: [0,0,0]
解释: 上图展示了初始的二叉树和修改每个节点的值之后的二叉树。
- 值为 3 的节点没有堂兄弟,所以值修改为 0 。
- 值为 1 的节点没有堂兄弟,所以值修改为 0 。
- 值为 2 的节点没有堂兄弟,所以值修改为 0 。
提示:
- 树中节点数目的范围是
[1, 10^5] 1 <= Node.val <= 10^4
Related Topics
- 树
- 深度优先搜索
- 广度优先搜索
- 哈希表
- 二叉树
题目链接: link
解答
本题的难度是 Medium.
这里的思路是先记下来每一层的总值, 然后再遍历一遍, 把每个节点的值替换成这一层的总值减去自己和兄弟节点的值. 这样就能得到结果了.
代码如下:
class Solution {
// 每一层的总值
public HashMap<Integer, Integer> hashMap = new HashMap<>();
public TreeNode replaceValueInTree(TreeNode root) {
if (root == null) {return null;}
TreeNode result = new TreeNode(0);
BFS_s(root, 0);
System.out.println(hashMap);
BFS_b(root, 0,result);
return result;
}
public void BFS_s(TreeNode node, int depth){
if(node.left != null){
hashMap.put(depth, hashMap.getOrDefault(depth,0)+node.left.val);
BFS_s(node.left, depth+1);
}
if (node.right != null){
hashMap.put(depth, hashMap.getOrDefault(depth,0)+node.right.val);
BFS_s(node.right, depth+1);
}
}
public void BFS_b(TreeNode node, int depth, TreeNode resultNode){
int temp=0;
if(node.left != null){
temp += node.left.val;
}
if(node.right != null){
temp += node.right.val;
}
if(node.left != null){
resultNode.left = new TreeNode(hashMap.get(depth)-temp);
BFS_b(node.left, depth+1, resultNode.left);
}
if(node.right != null){
resultNode.right = new TreeNode(hashMap.get(depth)-temp);
BFS_b(node.right, depth+1, resultNode.right);
}
}
}
很简单的思路,但是时间开销是 49ms, 只击败了18.29的用户. 因此考虑会不会是 HashMap这一步消耗了太多的时间, 因此这里进行了一些优化, 把 HashMap 换成了数组, 这样就不需要每次都去查找了.
class Solution {
// 每一层的总值
private int[] hashMap = new int[100_000];
public TreeNode replaceValueInTree(TreeNode root) {
if (root == null) {return null;}
TreeNode result = new TreeNode(0);
BFS_s(root, 0);
BFS_b(root, 0,result);
return result;
}
public void BFS_s(TreeNode node, int depth){
if(node.left != null){
hashMap[depth] = hashMap[depth] + +node.left.val;
BFS_s(node.left, depth+1);
}
if (node.right != null){
hashMap[depth] = hashMap[depth] + +node.right.val;
BFS_s(node.right, depth+1);
}
}
public void BFS_b(TreeNode node, int depth, TreeNode resultNode){
int temp=0;
if(node.left != null){
temp += node.left.val;
}
if(node.right != null){
temp += node.right.val;
}
if(node.left != null){
resultNode.left = new TreeNode(hashMap[depth]-temp);
BFS_b(node.left, depth+1, resultNode.left);
}
if(node.right != null){
resultNode.right = new TreeNode(hashMap[depth]-temp);
BFS_b(node.right, depth+1, resultNode.right);
}
}
}
此时的时间开销为 22ms, 击败了 58.29% 的提交, 原本到这里就想结束了, 但是突然一想, 为什么我要创建新的节点呢, 我直接在原来的节点上修改不就好了吗, 因此这里进行了一些修改, 把创建新节点的操作去掉了.
class Solution {
// 每一层的总值
private int[] hashMap = new int[100_000];
public TreeNode replaceValueInTree(TreeNode root) {
if (root == null) {return null;}
TreeNode result = root;
result.val = 0;
BFS_s(root, 0);
BFS_b(root, 0,result);
return result;
}
public void BFS_s(TreeNode node, int depth){
if(node.left != null){
hashMap[depth] = hashMap[depth] + +node.left.val;
BFS_s(node.left, depth+1);
}
if (node.right != null){
hashMap[depth] = hashMap[depth] + +node.right.val;
BFS_s(node.right, depth+1);
}
}
public void BFS_b(TreeNode node, int depth, TreeNode resultNode){
int temp=0;
if(node.left != null){temp += node.left.val;}
if(node.right != null){temp += node.right.val;}
if(node.left != null){
resultNode.left.val = hashMap[depth]-temp;
BFS_b(node.left, depth+1, resultNode.left);
}
if(node.right != null){
resultNode.right.val = hashMap[depth]-temp;
BFS_b(node.right, depth+1, resultNode.right);
}
}
}
这样只做了微小的修改, 但是让时间开销变成了 17ms, 击败了 90.86% 的提交. 心满意足