Leetcode 429 N 叉树的层序遍历
429.N 叉树的层序遍历
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
示例 1:
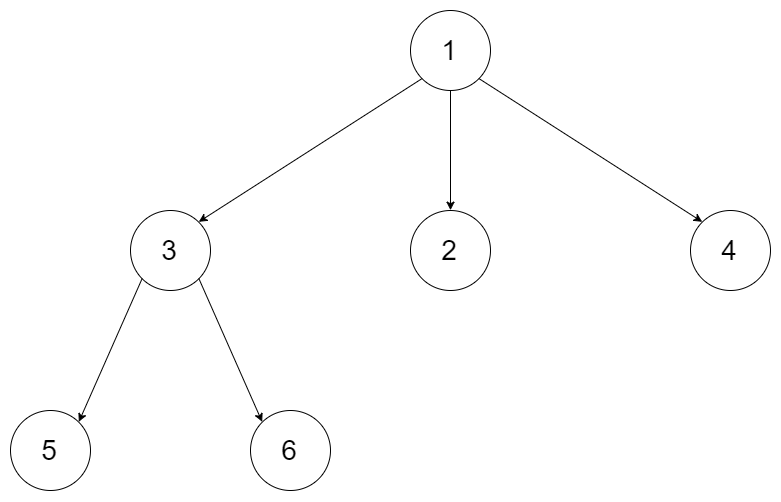
输入: root = [1,null,3,2,4,null,5,6]
输出: [[1],[3,2,4],[5,6]]
示例 2:
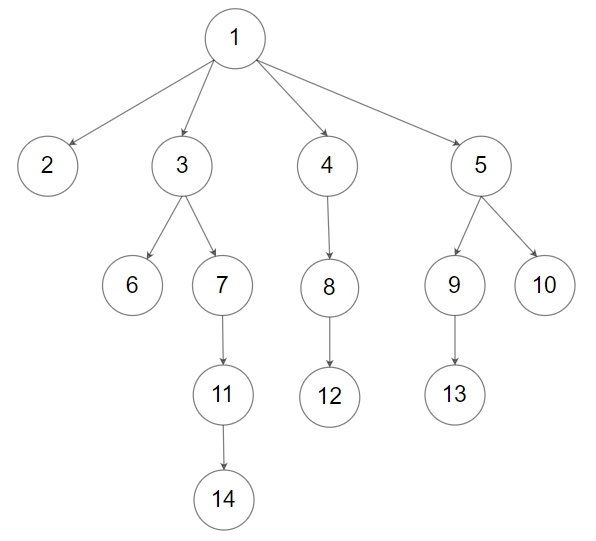
输入: root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出: [[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
提示:
- 树的高度不会超过
1000 - 树的节点总数在
[0, 10^4]之间
Related Topics
- 树
- 广度优先搜索
题目链接: link
解答
本题的难度是 Medium.
这题和层序遍历二叉树本质上是一样的, 只不过是多了一个子节点的遍历, 怎么这几天都是层序遍历.
代码如下:
class Solution {
private List<List<Integer>> result = new ArrayList<>();
public List<List<Integer>> levelOrder(Node root) {
subLevelOrder(root, 0);
return result;
}
private void subLevelOrder(Node node, int depth){
if(node == null) {return;}
if(result.size() < (depth+1)){
result.add(new ArrayList<>());
}
result.get(depth).add(node.val);
List<Node> children = node.children;
for (int i = 0; i < children.size(); i++) {
subLevelOrder(children.get(i), depth + 1);
}
}
}
耗时 0ms, 击败了 100% 的提交, 没想到这个题目居然80%的提交是 3ms? 可能是他们用的不是递归的方法? 怪, 看了一下也可能是因为他们用了一个队列, 这样反复的队列的存取会有更多的时间开销.