Leetcode 987 二叉树的垂序遍历
987.二叉树的垂序遍历
给你二叉树的根结点 root ,请你设计算法计算二叉树的 垂序遍历 序列。
对位于 (row, col) 的每个结点而言,其左右子结点分别位于 (row + 1, col - 1) 和 (row + 1, col + 1) 。树的根结点位于 (0, 0) 。
二叉树的 垂序遍历 从最左边的列开始直到最右边的列结束,按列索引每一列上的所有结点,形成一个按出现位置从上到下排序的有序列表。如果同行同列上有多个结点,则按结点的值从小到大进行排序。
返回二叉树的 垂序遍历 序列。
示例 1:
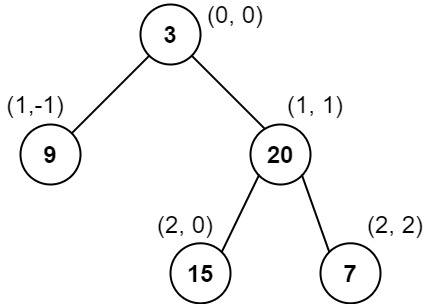
输入: root = [3,9,20,null,null,15,7]
输出: [[9],[3,15],[20],[7]]
解释:
列 -1 :只有结点 9 在此列中。
列 0 :只有结点 3 和 15 在此列中,按从上到下顺序。
列 1 :只有结点 20 在此列中。
列 2 :只有结点 7 在此列中。
示例 2:
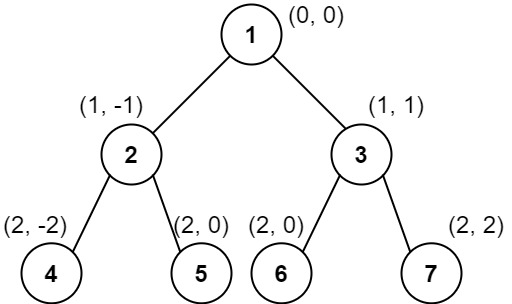
输入: root = [1,2,3,4,5,6,7]
输出: [[4],[2],[1,5,6],[3],[7]]
解释:
列 -2 :只有结点 4 在此列中。
列 -1 :只有结点 2 在此列中。
列 0 :结点 1 、5 和 6 都在此列中。 1 在上面,所以它出现在前面。 5 和 6 位置都是 (2, 0) ,所以按值从小到大排序,5 在 6 的前面。
列 1 :只有结点 3 在此列中。
列 2 :只有结点 7 在此列中。
示例 3:
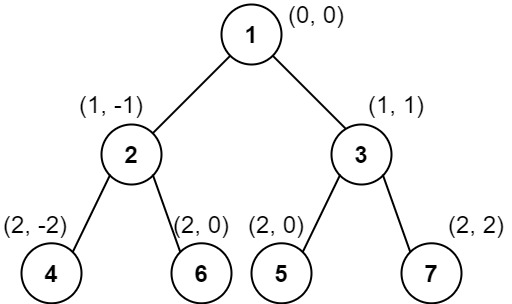
输入: root = [1,2,3,4,6,5,7]
输出: [[4],[2],[1,5,6],[3],[7]]
解释:
这个示例实际上与示例 2 完全相同,只是结点 5 和 6 在树中的位置发生了交换。 因为 5 和 6 的位置仍然相同,所以答案保持不变,仍然按值从小到大排序。
提示:
- 树中结点数目总数在范围
[1, 1000]内 0 <= Node.val <= 1000
Related Topics
- 树
- 深度优先搜索
- 广度优先搜索
- 哈希表
- 二叉树
题目链接: link
解答
本题的难度是 Hard.
虽然是 Hard, 但是感觉还行, 这个题目看起来暴力的思路还是很清晰的, 就是遍历一遍, 然后记录每个节点的位置, 然后再排序, 最后输出结果.
我的思路就是先记录当前的 row, 因为最后的结果是按照 row 来排序的, 然后再记录当前的深度, 最后再记录当前的值, 然后再排序. 看起来时间复杂度高, 但是实际处于同样的 row, 且深度相同的节点应该是非常少的, 绝大多数节点都不需要排序.
- 记录 rowMap, 每个 rowMap里放的是 depthMap, depthMap 里的是需要排序的List
- 每个节点遍历一遍存到 rowMap 后, 对每个depthMap里的List进行排序
- 排序后排序 key, 然后depthMap里的List即可.
代码如下:
class Solution {
// 第一个 Integer 是 row, 第二个 Integer 是 depth
private HashMap<Integer, HashMap<Integer, List<Integer>>> hashMap = new HashMap<>();
private HashMap<Integer, List<Integer>> tempHashMap;
private List<Integer> tempList;
public List<List<Integer>> verticalTraversal(TreeNode root) {
preOrder(root, 0, 0);
for (HashMap.Entry<Integer, HashMap<Integer,List<Integer>>> entry: hashMap.entrySet()) {
for ( HashMap.Entry<Integer,List<Integer>> valueEntry : entry.getValue().entrySet() ) {
Collections.sort(valueEntry.getValue());
}
}
List<List<Integer>> result = new ArrayList<>();
// 1. 获取 HashMap 的键集合
Set<Integer> keySet = hashMap.keySet();
// 2. 将键集合转换为数组
Integer[] keyArray = keySet.toArray(new Integer[keySet.size()]);
// 3. 对数组进行排序
Arrays.sort(keyArray);
for (int i = 0; i < keyArray.length; i++) {
tempHashMap = hashMap.get(keyArray[i]);
keySet = tempHashMap.keySet();
Integer[] tempKeyArray = keySet.toArray(new Integer[keySet.size()]);
Arrays.sort(tempKeyArray);
tempList = new ArrayList<>();
for (int j = 0; j < tempKeyArray.length; j++) {
tempList.addAll(tempHashMap.get(tempKeyArray[j]));
}
result.add(tempList);
}
return result;
}
private void preOrder(TreeNode node, int row, int depth){
if(node == null) {return;}
tempHashMap = hashMap.getOrDefault(row, new HashMap<Integer, List<Integer>>());
if (tempHashMap.containsKey(depth)){
tempList = tempHashMap.get(depth);
tempList.add(node.val);
} else {
tempList = new ArrayList<>();
tempList.add(node.val);
tempHashMap.put(depth, tempList);
}
hashMap.put(row, tempHashMap);
preOrder(node.left, row-1, depth+1);
preOrder(node.right, row+1, depth+1);
}
}
耗时 2ms, 击败了 98.88% 的提交, 应该还可以优化? 毕竟对象操作太多了. 但是已经满足了.